Web Technologies
HTML
HTML stands for Hypertext MarkUp Language. If you have never used HTML before click here to find out about the basics.
Cascading Style Sheets
Cascading Style Sheets (CSS) is a style sheet language used for describing the style of a document written in a markup language such as HTML. CSS is a cornerstone technology of the World Wide Web,
There are several ways to use CSS. From inline which has the smallest scope to external which can be linked to several web pages.
Inline CSS

This is where one or more styles are added directly into an HTML tag. Note this only affects that particular tag.
<p style="color: blue; text-align: center;">This is a heading</p>
Internal CSS
This is where style is defined inside the <style> element within the head section. This will affect all tags of the specified type. So in the example below. All heading 2 tags will be pink and center aligned.
<head>
<style>
body {
background-color: linen;
}
h2 {
color: pink;
text-align: center;
}
</style>
</head>
External CSS
This is the most effective when working with multiple web pages. Style formatting is saved into one or more seperate style sheets. The style sheet is then linked to one more HTML files by adding the following code to the head section:
<head>
<link rel="stylesheet" href="Style.css">
</head>
This means that all web pages will then have the same style. External style sheets have the following advantages:
- Content and formatting are kept separate.
- It saves time when making a website.
- It ensures that a whole website will have the same style and supports a consistent organisational housestyle.
- If the external style sheet is updated it will affect the whole website, so it's quick and easy to change your mind on a colour scheme, choice of font etc.
- Stylesheets can be created for different themes, or different devices.
- You can link more than one style sheet. For example one for the whole organisation, one for a department. The style sheets are used in the order in which they are linked. So in the example below styles from the art department style sheet will be used first. Then the school style sheet will be checked for any styles not defined in the art department.
<head>
<link rel="stylesheet" href="SchoolStyle.css">
<link rel="stylesheet" href="ArtDepartment.css">
</head>
Style Selectors: IDs and Classes
IDs and Classes are two of the most commonly used style selectors used to define the style of HTML elements.
The Class Attribute
The class attribute allows you to reference a class name in a style sheet. Use a dot to define a class. Click here for an example.
.myID {
background-color: black;
color: white;
text-align: center;
}
The ID Attribute
The ID attribute is used to define a unique id for an HTML element. Use a # to define an ID. You can then set styles for that ID attribute. Click here for an example.
#myID {
background-color: black;
color: white;
text-align: center;
}
The differences between ID and Class
Both allow you to set styles and the only different is that you either define with dot or #, so why have two ways? Here are the subtle differences:
IDs:
Elements can only have one ID. IDs must be unique within the HTML document.
Since there can only be one ID use this if you want to ensure that the style can not be overwritten. IDs take precedence over classes.
So you are likely to use it for a specific section of your webpage e.g. the header. They are the “hash value” in a URL. If you have a URL like http://mywebiste.com#questions, the browser will attempt to locate the element with an ID of questions and will automatically scroll the page to show that element.
Classes:
You can use the same class multiple times.
You can use multiple classes on the same element.
For the Exam: CSS Styles
Here are the CSS styles from the exam board. You will need to know at least these for the exam.

JavaScript
Many web pages need to interact with the user. JavaScript allows you to validate and process user input. It can also create dynamic content. It is mainly used client side. Code is interpreted by the client's browser.
Here's an example of embedded JavaScript directly written into an HTML web page:
<script>alert("Hello World!");</script>
Inputs
- Alerts are a simple way to have a message pop up on the web page.
- The document.write function will insert text directly into the web page.
Functions
function DisplayGreeting() {
alert ("Hello World!");
}
Functions can take parameters and return data.
An Event Handler:
<button onclick="say_hello()">Press me!</button>
Creating a variable:
var count = 15;
Using Selection:
if (count >= 100) {
alert("Too many people for this party");
} else if (count > 75) {
alert("Almost at capacity.");
} else {
alert("Allow entrance.");
}
Using Iteration
Count Controlled Loops:
for (var i = 0; i <10; i++)
{
document.write("Howdy");
}
Condition Controlled Loops:
var i = 0;
while (i < 10) {
document.write("Woohoo");
i++;
}
Arrays
var fruits = ["apple", "pear", "orange"];
Arrays can grow. Push a banana onto fruits:
fruits.push("banana");
Checkthe array length:
fruits.length
PushState
The history.pushState() method allows you to add an entry to the web browser's session history stack. Here's the syntax of the pushState() method: history.
JavaScript in an external file.
You can create a Javascript file and link it into your web page. This would allow you to use the same code for multiple web pages.
<head>
<script src="my_scripts.js"></script>
</head>
Server Side and Client Side Processing
ClientSide
Client side processing takes place in the web browser. JavaScript can be used to make web pages more interactive. JavaScript is used mainly for client-side processing.
Advantages:
Client side processing doesn’t require data to be sent back and forth meaning code is much more responsive. So it's best for games.
Disadvantages:
However the browser may not run the code because if it doesn't know how to. The user can also disabled client side code.
So client side is best when it is not critical that the code runs.
ServerSide
Server-side processing where code is executed on the web server and the results are sent back to the client in HTML to be displayed in the web browser.
Advantages:
This means we are no longer relying on the browser to have the capabilities to run the code. So it is should be used for critical code.
It also prevents code from being copied (copyrighted code), changed or circumvented. So this is best if it's critical code that must be run. Or when secure data needs to be accessed. Data passed to the server can also be checked carefully.
Disadvantages:
However,this means that the server is doing more work which will increase the cost of hosting the website.
Validation checks - which is best server or client?
The answer is both. The client can give a quick response. The server can then check again in case the client side has been circumvented.
Indexing
Indexing is the process by which a search engine adds web content to its index, so that it is faster to find relevant web pages when searching. So when you are searching for a web page, the search engine runs your search against this index rather than all pages on the web.
Indexing is the process of creating this index. It does this by "crawling" through the pages looking for search keywords, metadata, meta tags etc. to tell the search engine where to rank the page.
Web crawler or a spider is a program that visits site from an existing list and then on by following page links. It records information (e.g. text, meta tags) and the position of each word within the page. It then stores this in an index.

Meta tags are built into web pages. Here is an example in the head section of an HTML web page.
The Page Rank Algorithm
When a search engine attempts to find web pages by crawling through the world wide web it needs to find the most relevant pages. To do this it might use the page rank algorithm to ranks web pages in the order that they should be shown. Page rank is the first and most common algorithm but there are others.
The algorithm works by assuming that the more pages that link to your webpage.. the more important your web page is.
A page's ranking is based on:
- How many incoming links it has from other web pages.
- The rank of those linked pages.
The algorithm is iterative, it is run over and over again to gain a more precise estimated values.
A directed graph is a good way to represent this.
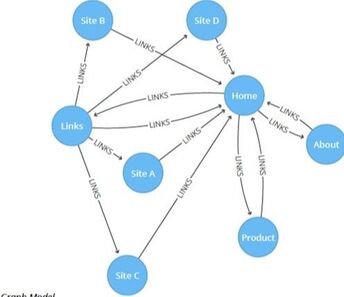
Parts of the Page Rank Algorithm
- PR(A) - the PageRank of page A.
- C(Tn) - the total count of outbound links from page n, including the inbound link to page A. Each web page has a notional (suggested) vote of 1 shared between all pages it links to.
- PR(Tn)/C(Tn) - the share of the vote page A gets from pages T1 to Tn.
- d - the damping factor (see below).
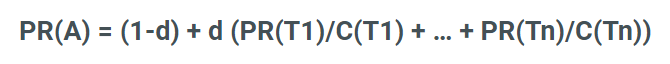
Don't worry, you don’t need to memorise the full algorithm. You do need to know the parts.
The Damping Factor
Built into the algorithm is the assumption that a web surfer randomly clicking on links will eventually stop. The damping factor is the probability of between 0 and 1 that a user will not follow a link. It is usually set to 0.85 which equates to six click through links.